Recent articles
Project Harbor at Open Source Summit India and KubeCon + CloudNativeCon India 2026
Project Harbor at KubeCon + CloudNativeCon Europe 2026 in Amsterdam
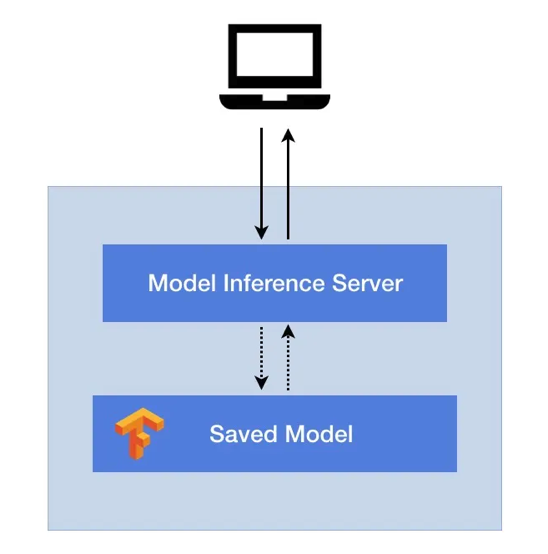
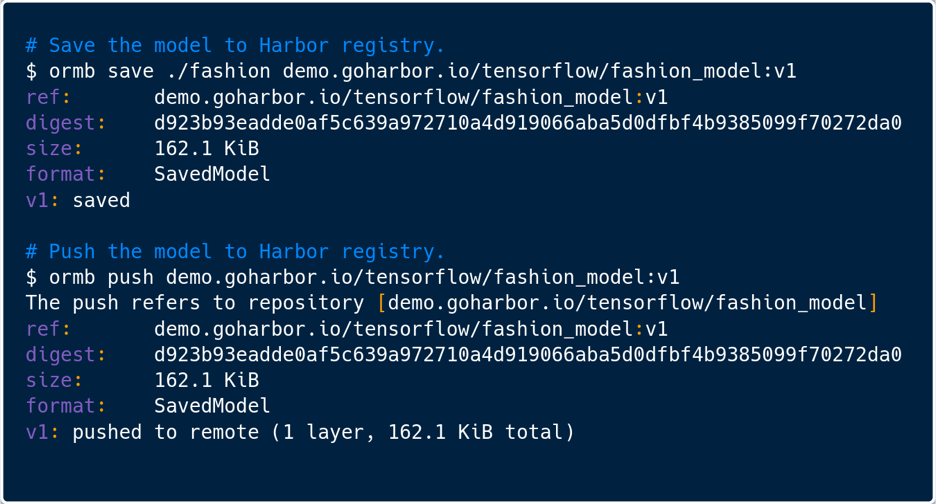
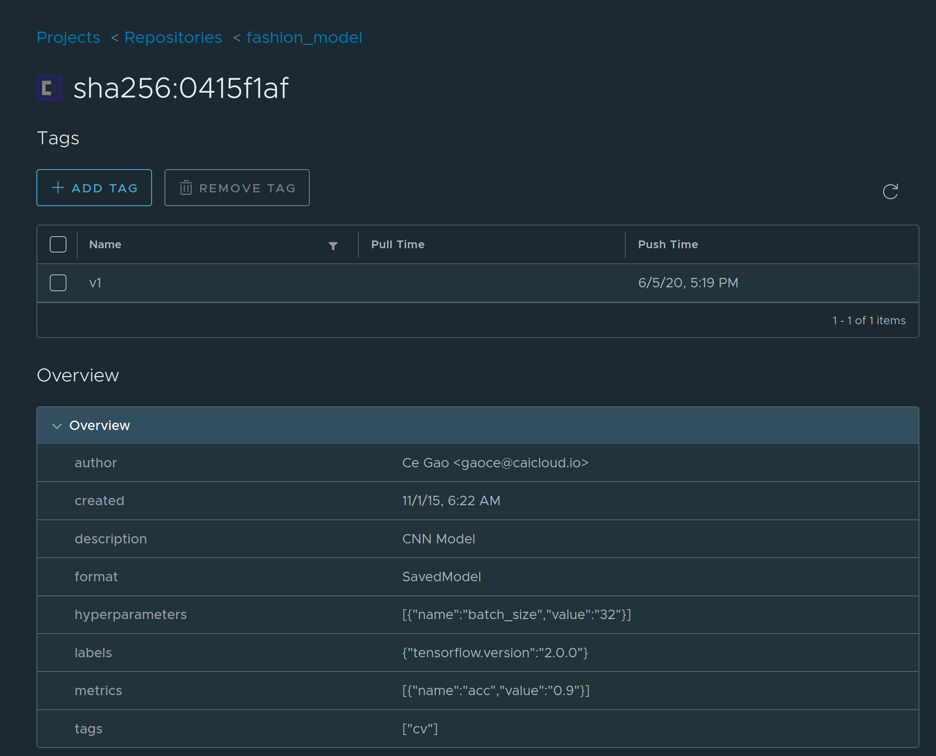
Cloud-Native AI Model Management and Distribution for Inference Workloads
Gitless GitOps: Using OCI Registries as a Secure, Trusted Hub for Multi-Zone Replication of Signed Artifacts